

Reportase Topik I: Analisis Data - Data Klaim dan Diagnosis Melalui Data sampel BPJS Kesehatan 2015 - 2018
Pelatihan Penulisan Pengolahan, Analisis, dan Visulisasi Data Kesehatan
Hari Pertama: 16 Februari 2021
Pada Selasa (16/02/2021) diselenggarakan Pelatihan Pengolahan, Analisis, dan Visualisasi Data Kesehatan hari pertama topik ke-1 tentang analisis data - data klaim dan diagnosis melalui data sampel BPJS Kesehatan 2015 - 2018. Acara berlangsung pukul 13.00 – 15.00 WIB di Gedung Litbang, FK – KMK UGM dan disiarkan melalui zoom meeting. Pelatihan ini merupakan hasil kerja sama antara Pusat Kebijakan dan Manajemen Kesehatan (PKMK) FK - KMK UGM bersama dengan World Health Organization (WHO) Indonesia dalam program penguatan dan pengembangan kebijakan Kesehatan. Beberapa data yang diolah dalam rangkaian pelatihan ini hingga Maret nanti antara lain data sampel BPJS Kesehatan, data SKDN, dan data - data KIA.
Outcome dari pelatihan ini diantaranya peserta dapat mengenali dan memahami berbagai data kesehatan yang ada dan mampu melakukan pengolahan, analisis, dan visualisasi data rutin berdasarkan contoh yang diberikan dalam pelatihan. Dua orang narasumber hadir dalam pelatihan ini yaitu Insan R. Adiwibowo, M.Sc. yang merupakan peneliti dari PKMK FK - KMK UGM dan Hermawati Setiyaningsih, S.Si selaku statistician dan pusat Kebijakan Pembiayaan dan Manajemen Asuransi Kesehatan (KPMAK) FK-KMK UGM. Pelatihan dimoderatori oleh Muhammad Hafizh Hariawan, S.Gz, MPH.
Sesi 1 – Pengantar Data Sampel BPJS Kesehatan
Hermawati Setiyaningsih, S.Si
 Herma memulai materinya dengan menjelaskan bahwa data sampel awal yang diluncurkan BPJS Kesehatan yaitu tahun 2015 - 2016, kemudian BPJS meluncurkan data lagi yaitu data tahun 2017 - 2018. Sumber data ini berasal dari peserta dan fasilitas kesehatan, baik tingkat pertama maupun rujukan. Kemudian data ini masuk ke senter BPJS untuk dianalisis agar memudahkan dalam pembacaan dan interpretasinya. Terkait dengan metode penarikan sampel, data ditarik dari peserta dengan tiga kategori yaitu keluarga yang pernah mengakses FKTP, keluarga yang pernah mengakses FKRTL, dan keluarga yang belum pernah mengakses pelayanan kesehatan.
Herma memulai materinya dengan menjelaskan bahwa data sampel awal yang diluncurkan BPJS Kesehatan yaitu tahun 2015 - 2016, kemudian BPJS meluncurkan data lagi yaitu data tahun 2017 - 2018. Sumber data ini berasal dari peserta dan fasilitas kesehatan, baik tingkat pertama maupun rujukan. Kemudian data ini masuk ke senter BPJS untuk dianalisis agar memudahkan dalam pembacaan dan interpretasinya. Terkait dengan metode penarikan sampel, data ditarik dari peserta dengan tiga kategori yaitu keluarga yang pernah mengakses FKTP, keluarga yang pernah mengakses FKRTL, dan keluarga yang belum pernah mengakses pelayanan kesehatan.
Perilaku pemanfaatan JKS diasumsikan memiliki korelasi tinggi di tingkat keluarga dengan adanya aturan pendaftaran JKN sekeluarga sebagai satu kesatuan. Oleh karena itu, proses sampling menggunakan keluarga sebagai unit sampling atau unit penarikan sampel, bukan individu peserta. Data pelayanan peserta JKN memuat berbagai informasi ukuran kesehatan dan pembiayaan. Jumlah peserta yang mengakses pelayanan lebih sedikit daripada peserta yang belum pernah mengakses pelayanan melalui JKN. Oleh karena itu, diperlukan proses over sampling terhadap kelompok tersebut. Proses sampling tidak dilakukan secara proporsional agar data perilaku terkait layanan memiliki jumlah yang cukup banyak.
Herma juga menjelaskan tentang pembobotan. Bobot diperlukan untuk menyamakan probabilitas peserta JKN terpilih sebagai sampel. Pehitungan bobot dilakukan dua tahap. Tahap pertama, yaitu bobot dasar keluarga, untuk menyamakan probabilitas keluarga peserta JKN terpilih sebagai sampel. Bobot = 1/probabilitas terpilih. Tahap kedua, bobot dasar individu peserta JKN. Bobot individu dihitung dengan cara membagi bobot keluarga dengan jumlah anggota keluarga.
Struktur data sampel
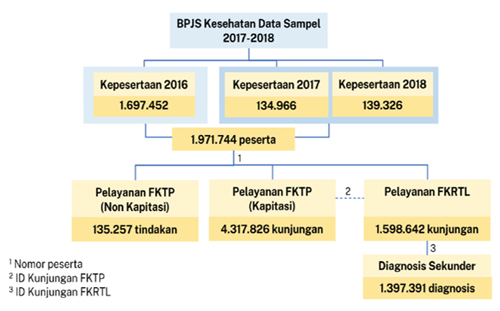
Sesi 2 - Analisis Deskriptif dari Data Sampel BPJS Kesehatan
Hermawati Setiyaningsih, S.Si dan Insan R. Adiwibowo, M.Sc
Sesi ke-2 diisi dengan praktik analisis deskriptif dari data sampel BPJS Kesehatan tahun 2018 menggunakan Stata. Kemudian pelatihan dilanjutkan dengan sesi diskusi. Peserta antusias dan terlibat aktif dalam proses tanya jawab.
link pelatihan selengkapnya dapat diakses pada link berikut
Reporter: Widy Hidayah (PKMK)
Tags: reportase,, 2021,